
Quickly, here's a list of topics covered in this document:
Once a common version has been chosen, triplets of files from each of the three versions are found and each triplet is individually considered. The next section of this document describes the choices presented to the user at this time, possible error conditions, and logic behind the default actions.
Sometimes you don't want to merge everything, this is called a partial merge. The third section describes the issues and problems involved with partial merges, and how PRCS's default actions help you deal with these situations.
After you've finished one merge, nothing is stopping you from merging again. This is, in fact, not an uncommon thing to do. The fourth section describes how the algorithm for choosing a common version is altered for subsequence merges.
Sometimes PRCS just can't decide what to do for you, and sometimes you've mixed things up so that merge either tells you to do something by hand or asks you to make a choice where something is ambiguous. Even worse, sometimes you want to do something PRCS things you probably don't. You need to know how to override certain default actions. The fifth section describes these merge difficulties and skilled merging.
Once you've merged to your heart's content and want to check in another version, you've got a few extra things to think about at checkin. In fact, in most non-trivial cases you need to think about what you're doing before you perform the merge. The sixth section describes issues involved with checkin after merging. It also describes the algorithm for choosing a parent version in general.
There's no way to make the most out of a version control system without understanding these issues. Hopefully, describing merge in a semi-tutorial way will help people lose their fear of advanced version control features.
In each diagram, time runs from the bottom to the top. The equality sign indicates that the version checked in is equivalent to a version in the repository. The wavey line indicates a checkin. Arrows heading up are work or progress in a project version. Arrows heading down indicate a parent version. When two upward arrows meet, a merge has been performed. The notation can get quite cluttered, so often diagrams will leave out parts which are clear or not important. A checkin looks like so:
To unclutter the diagrams, the above checkin will be abbreviated as follows:
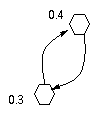
With the diagrams explained, we need some concrete names. The two developers are named A and B. They operate on a project named P, and initially each developer has a copy of the initial version, 0.1. Continuuing with the simple scenario, A modifies his copy of 0.1 and checks in 0.2. B modifies his copy of 0.1 and then wants to reconcile his changes with those made by A, and so must merge. In this case, B has the working version which is a modified set of working files derived from 0.1. The selected version is 0.2, the version B wishes to reconcile changes with. The common version is 0.1, since both the working and selected versions were derived directly from it. In this case, the common version was quite obvious.
To be more precise requires a definition of the parent-version and the algorithm PRCS uses. Each time a version is checked in it has one or more parent versions set. The sequence of parent versions estabilishes an ancestry graph which is directed and contains no cycles (ancestry is a partial ordering). A version is an ancestor of another if it can be reached by following zero or more parent versions. In the simple example case, merge picks the common version to be the only common ancestor of the both the working and selected versions. In the general case, the closest ancestor is chosen from the set of versions which are ancestors of each of the parent versions of the working and selected versions. If unique, the common version is the element of this set of common ancestors which is not an ancestor of any other element in the set--the youngest ancestor. If the set of common ancestors is not empty, it must contain at least one youngest ancestor since the graph is acyclic. If there is more than one youngest ancestor, merge will report an ambiguity and ask you to choose a common version. The situation where there is more than one youngest ancest or is difficult to obtain, and not recommended. It can only arise when there is more than one source in the graph, meaning that versions were imported into branches with the empty version as their parent. If the set of common ancestors is empty, the common version is chosen as the empty version in the selected branch (this choice over the working branch is arbitrary; recall that all branches have an empty version with minor version 0).
When the merge is complete, B is left with a (possibly) modified set of working files and a project file which has recorded in it the events of the merge. The repository has not been modified! After the merge, B checks in version 0.3. Version 0.3 has two parent versions, 0.1 and 0.2. The first parent records the original version version 0.3 was derived from, since B started with 0.1. The sequence of events is shown below:

This sort of merging is okay, but I don't recommend it. There are too many ways it can go wrong. Since the working files input by B are the only copy of the files he wishes to merge, any accidents can cause him a lot of trouble. PRCS is careful not to delete anything, but accidents happen. It is prudent to for B to first check his working files into a branch off of 0.1. Many people I talk to about using PRCS seem to be afraid of creating branches. They are really quite simple--unlike, perhaps, other version control systems. Instead of playing out that scenario, instead lets have B make several checkins onto another branch named B. He might, for example, type:
$ prcs checkin -l -r B PPRCS will confirm the creation of a new branch and check in version B.1. Afterward, B continues development and checks in 2 more branches, leaving the tip of the B branch at minor version 3. Since then, A has continued developing on major branch 0, and has checked in version 0.3. Now B would like to return his changes to the main branch so that A can use his changes. He merges against major version 0.3 with the command:
$ prcs merge -r 0The common version is obviously still the same, 0.1. Nothing changed except the number of points where B checkpointed a version. Suppose B completes the merge and checks in version 0.4, the parent versions are B.3 and 0.3. A diagram follows:

B can then continue development on the 0 branch and check in 0.5, or he can create another branch at 0.4 similar to the B branch, for a series of checkpoints before returning to the 0 branch again. There may be a reason for B to return to developing on the B branch, where he left off at B.3. When this type of development occurs, it is usually referred to as a vendor branch. The reason it is called a vendor branch is that it describes how to track local changes to another person's (the vendor's) data. PRCS has no knowledge of a vendor branch, however, instead its merge algorithm is powerful enough to have 1, 2, or even more vendor branches without special consideration for what is and isn't a vendor branch. The vendor branch scenario describes the case where B continues development on the B branch after B.3 has been merged with 0.3 because it's not actually B doing the merge, B has sent the sources for B.3 and are merged into the local changes made by A; B continues development at B.3.
For clarity, lets examine the vendor branch scenario with names changed; the vendor branch is named V, the local branch is named L. The vendor branch starts with release 1.0 of a piece of software. The initial version is checked in as V.1. L then checks out V.1, makes some local modifications and checks in as L.1. The vendor then releases 1.1 which gets checked in as V.2. See the documentation for exactly how the second import works if you're unclear. V.2 then gets merged against L.1, producing L.2. This process repeats, the important point is how the common version is chosen at each merge. The common versions are the vendor releases. When V.3 is merged against L.2, V.2 is the common version, and so on. A diagram follows, where working versions and parent version pointers have been omited for clarity.

Remember that there is nothing special about a vendor branch. Another developer could just as well treat the L branch as a vendor branch.
There is more to choosing a common version when multiple merges are performed between checkins. They will be covered later.
The general idea is that whenever a change has been made between the selected version and the common version that hasn't been made to the working version it should be incorpoorated into the working version, where to incorporate a change means either to delete a file, add a file, replace a file, or merge a file. When PRCS detects that there may be a change you would like to incorporate into the working version it prompts you to take each of the possible actions and continues. PRCS does not prompt the user for X of the 14 cases below, these are listed as "no prompt", these are the cases where there is no change to be incorporated into the working version. There are five default values when PRCS prompts the user--the 4 actions listed above plus nothing, this case is different from "no prompt" because it indicates that there have been changes but PRCS can't recommend what to do one way or another and that you probably want to ignore the change. Whenever PRCS modifies or deletes a file, it first saves the original copy into the directory "obsolete". PRCS finds the first available filename by appending ".vN" to the filename and finding the first available N, leaving numbered backups of the file.
First, the 5 cases where all files exist:
Except for merge, the merge actions are self explanatory. The merge action runs the diff3 program on the three files. PRCS uses GNU diff3, which is described in the info pages for GNU diff3. Briefly, it finds the insertions and deletions between the common and selected file and the common and working file. It then outputs a file containing both sets of insertions and deletions, placing markers around the output when the two changes conflict. To help deal with conflicts, PRCS reports a conflict and you may edit the file immediately by setting the PRCS_CONFLICT_EDITOR environment variable.
PRCS records which files you have merged by recording them in the project file. If you quit a merge in the middle, it will be marked incomplete in the project file. This way, when you restart a merge you do not end up considering the same file twice. As mentioned before, files may be matched by name or by file-family. Even so, files are recorded by name. This defines the behaviour for the somewhat pathological case where a file groups by name and by file-family--don't do it, it causes other problems described later.
Second, you may wish to merge against certain files in another version. This is a somewhat nefarious affair. But if you're ready to deal with the problems that can arise, its something you may want to do occasionaly. The problem is, as far as PRCS is concerned the next time you attempt a checkin the version is in an inconsistant state, halfway between one version and the other.
In any case, if you attempt to check in a version which has not been completely merged, checkin will ask you several questions. First, it asks if you really want to checkin a partially merged version. If yes, checkin asks whether to consider the version merged or not. The question really asks whether or not the partially-merged-against version should be considered a parent of the new version or not.
Suppose there are two branches named L and M, where L.1 and M.1 share a common parent. All versions contain two files, named F and G. A developer with version L.3 does a partial merge against M.3, merging only the file F, not G. This might happen if the developer knew that the file F had some changes which did not depend on G, and he wanted those changes but not the changes in G. He might type:
$ prcs merge -rM.3 P F # merge takes place... $ prcs checkin PCheckin asks whether to consider M.3 as a parent. If yes, then by default PRCS checks in as version M.4. Later, suppose M.4 gets merged against L.4. The common version chosen is L.3, meaning the common version chosen for merging the file G is incorrect.
If M.3 is not considered as a parent, then PRCS checks in as L.4. Later, if L.4 is merged against M.4 (or M.3), the common version is the common parent of L.1 and M.1. The file chosen for merging the file F is incorrect.
The developer may also want to keep M.3 as a parent and checkin as L.4. To do this, he types:
$ prcs checkin -rL PSupplying "-rL" forces PRCS to checkin as L.4 whether M.3 is considered a parent or not. If yes, then a later merge against the M branch will produce a common version M.3. The file chosen for merging the file G is incorrect.
As you can see, checking in incomplete merges can create problems. If you don't intend to do later merges between the two branches, or if you really pay attention to what you're doing, you can accomplish the desired effect.
The common scenario is this: developers A and B check out the same version, 0.1. A checks in 0.2 and B merges. A checks in 0.3 and B merges again. This repeats until B checks in a version. Each version B merges against is added to the list of parents. For the second merge, B's working files have two parents, 0.1 and 0.2. When he merges against 0.3, according to the algorithm defined above, it picks the youngest element of the set of common versions, 0.2. This is the correct version, since B's files were most recently reconciled with version 0.2.
In a less common scenario, an N-way merge is performed between different branches. First, some facts. Order matters. If it were not for conflicts, it would be possible to say something about the dependence on order. Here, conflicts refers to more than just those sometimes produced when a merge action is taken on a group of files, it also refers to places where file additions or deletions conflict with each other. If there are no conflicts, however, order should not matter. I say "should not" because diff3 can get confused, so you still have to be aware of what you're doing. The important point is that parents are updated after each merge, regardless of whether a checkin is performed or not, so each subsequent merge takes place as if it had been checked in first. As an example, consider the following diagram.
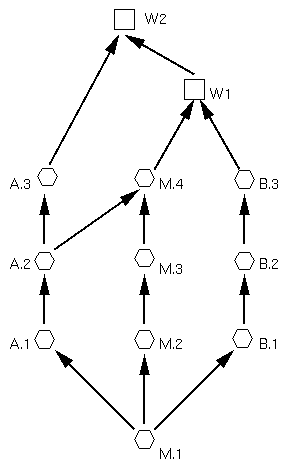
Here M.4 is merged with B.3, producing W1. The set of common ancestors for this merge contains only M.1. After, W1 is merged with A.3. The set of common ancestors contains both A.2 and M.1. A.2 is the youngest and is chosen as the common version.
When you attempt to merge against a new version following an incomplete merge, PRCS asks the same question as it would at checkin, should the partially merged version be considered a parent.
Specifically, PRCS will not let you merge a file twice. If you want to force a second merge, run merge with --skilled-merge and PRCS will ask for each file which has already been considered whether to reconsider the file.
Sometimes PRCS can't help you. When you mix partial merges where files are selected by name or by file-family, it is possible to end up in a situation where a file should to be added that already exists if grouped by the other selection criteria. In this case, PRCS will print a message explaining the situation and tell you to deal with the problem by hand.